它最大的特点在于人机交互,用户可以通过与AI的交互,逐步引导并补充信息,从而生成更符合个人需求的文章。
我也在推广上做了一些尝试,希望让更多人了解并体验这个全新的AI写作工具。
为什么开发AI写作功能?
今年的市场环境与去年相比已发生巨大变化,简单的AI对话产品没有了竞争力,市面上充斥着众多竞品,大厂APP功能更强大且免费。因此,我迫切需要开发一个更具竞争力的东西出来。
我重新思考了产品方向,并调研AI市场的用户需求。一方面,我参考了风投投资的创业公司,收集大量AI方向创业公司的信息,例如YC的投资名单,从中整理出一些可行的产品方向。
另一方面,我尝试分析产品积累的用户对话数据(所有数据均为匿名,仅用于内部调研和产品改进,不涉及个人隐私问题)。因为数据量非常大,我用了一些分析方法,比如词频、词云、主题模型和关键词统计。结果发现,对话问答和写作这两方面的需求都很强,大约各占了1/3,其他需求则分布在不同的小领域里。

综合考虑,AI写作的需求很广泛也很重要,所以我决定先开发AI写作这个功能。
AI写作应该做成什么样?
请看AI的回答:

我分析了市面上的AI写作产品,发现 Notion AI 和 WPS / Word AI 比较符合AI交互式写作的特点,其他大部分产品都是AI文章生成器,直接生成文章,不支持交互式写作。还有一些产品是针对特定写作领域的,比如论文写作和小说写作。
我认为,AI写作的最佳方式是人与AI的交互。用户可以逐步指导AI如何改写,从而生成更符合需求的文章。而那种直接生成文章的工具,往往很难写出用户满意的好文章。
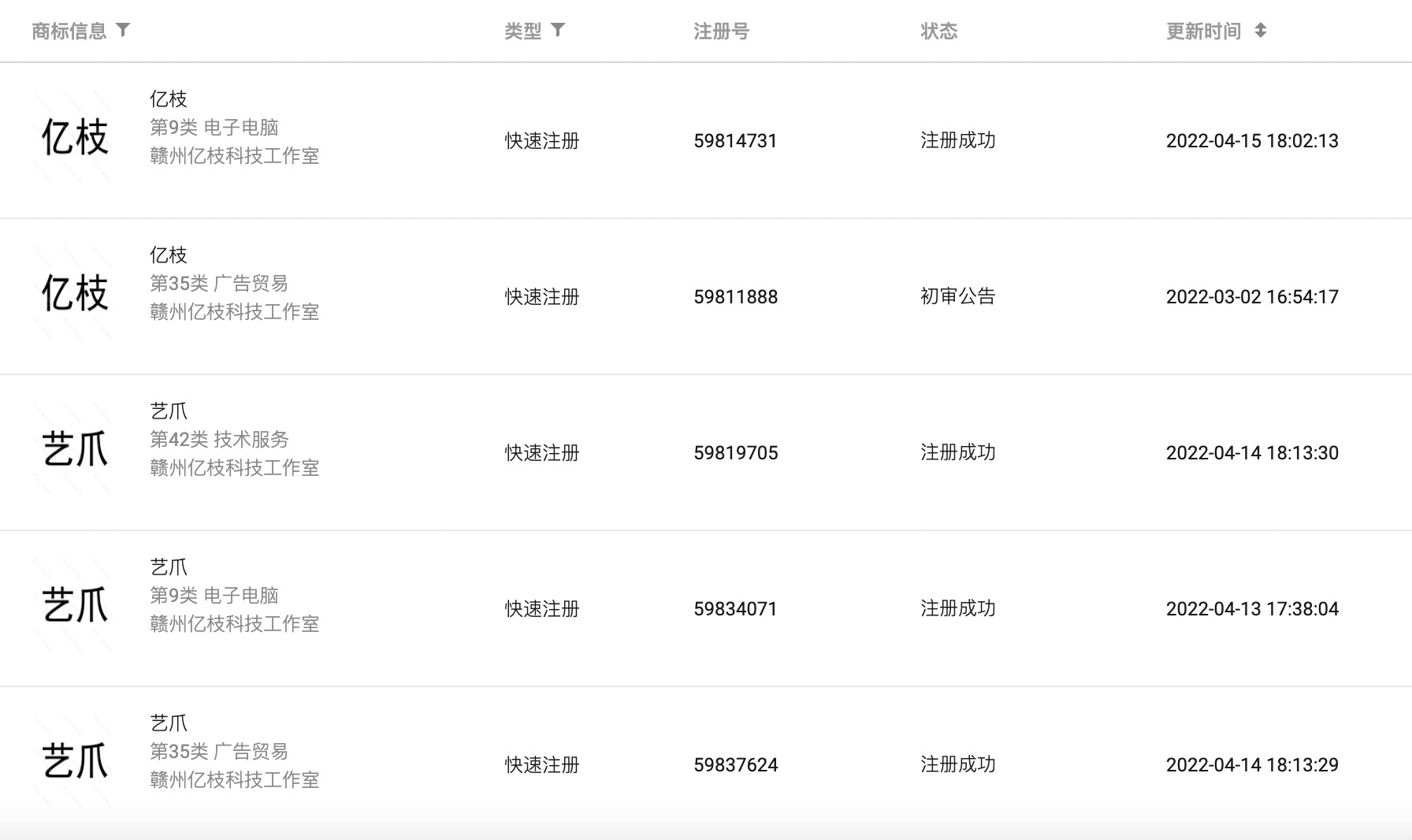
艺爪AI写作上线和推广
经过一个多月的开发,艺爪AI写作在5月底完成上线了,第一版只适配了电脑端,随后开发适配了移动端界面。经过近一个月的迭代和优化,现在产品已经比较好用了。感兴趣的朋友可以通过下面链接访问:
产品上线后,接下来要考虑的就是推广问题了。要让更多人知道我们的产品,特别是那些真正需要它的人。
我本来的计划是,一方面找代理商合作推广,另一方面我自己也通过自媒体来宣传。但现在AI的热潮已经消退,市场回归理性,推广起来比以前难了,我们的产品竞争力也没有那么强,所以代理商不太愿意推广了,我们得自己想办法去做市场推广。
虽然渠道销售可以放大流量,但在产品标准化之前,我们还是得直接面对用户。参考 初创公司的销售模式-奇绩创坛。
AI算法备案
还有一个好消息,艺爪AI成功通过了网信办算法备案。

艺爪AI助手合规运营,安全、可靠,更加放心使用!
后续计划
-
利用同一套跨平台代码,上架艺爪AI助手的APP端、桌面客户端,为用户提供更好的使用体验。
-
深入探索AI写作的市场需求,不断迭代产品,提升用户体验,让AI写作更加贴合用户的实际需求。
现在,想请教大家一个问题:你心目中理想的AI写作功能应该是怎样的?欢迎在评论区留下你的想法,期待与你共同探讨和进步!
最后
通过「RSS阅读器」或者关注公众号「自宅创业」可以订阅博客更新,也可以在 关于我 页面找到我的联系方式,欢迎交流!
]]>

















{kind=link}